AI powered Knative Functions for Inference with Llama Stack¶
Author: Matthias Weßendorf, Senior Principal Software Engineer @ Red Hat
This post will describe how to create Knative Functions for Inference with Llama Stack.
Llama Stack¶
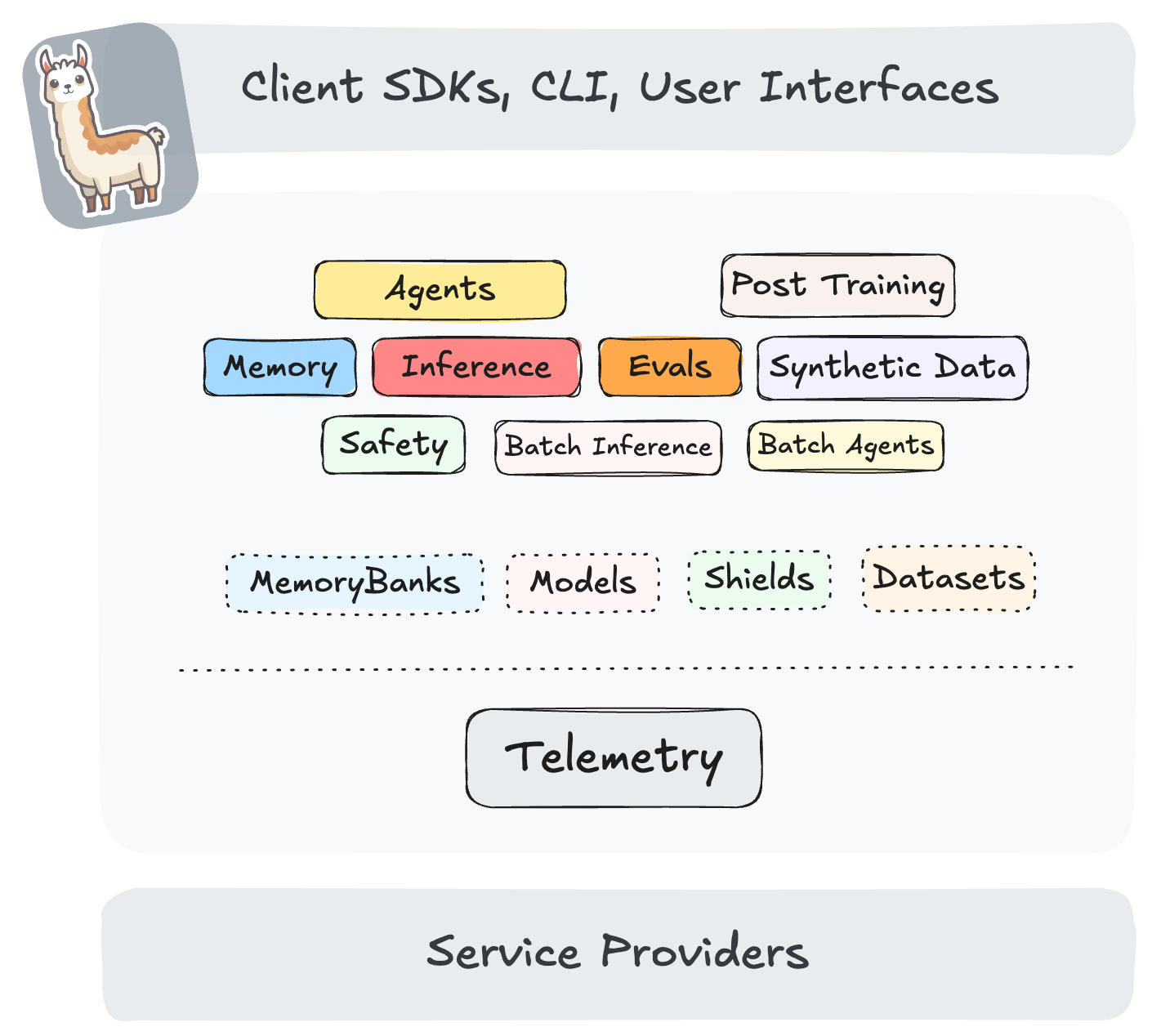
Llama Stack is an open-source framework for building generative AI applications. It aims to define and standardize the core building blocks for generative AI apps. For this it provides a unified set of APIs and building blocks:
- Unified API layer for Inference, RAG, Agents, Tools, Safety, Evals, and Telemetry.
- Plugin architecture to support the rich ecosystem of implementations of the different APIs in different environments like local development, on-premises, cloud, and mobile.
- Prepackaged verified distributions which offer a one-stop solution for developers to get started quickly and reliably in any environment
-
Multiple developer interfaces like CLI and SDKs for Python, Node, iOS, and Android
-
Standalone applications as examples for how to build production-grade AI applications with Llama Stack
Llama Stack setup for Kubernetes¶
For Llama Stack an easy way to get started is using Ollama as the inference provider for a Llama Model. The Llama Stack Quickstart shows how to do this for a local environment. But we are using Kubernetes! For k8s, you need:
For convenience I have created a Github repository that contains scripts for an easy setup. See the Llama Stack Stack repo for more details.
Portforwarding for local access to the Llama Stack¶
For local development it is recommended to enable port-forwarding for the Llama Stack server:
kubectl port-forward service/llamastackdistribution-sample-service 8321:8321
Now your scripts can access it via localhost:8321:
http localhost:8321/v1/version
HTTP/1.1 200 OK
content-length: 19
content-type: application/json
date: Fri, 04 Jul 2025 08:33:10 GMT
server: uvicorn
x-trace-id: edc0436a6bc932434f34d3d3ce1be182
{
"version": "0.2.9"
}
Note: The APIs of Llama Stack are fast evolving, but it supports a docs endpoint (in our case, http://localhost:8321/docs). You can also use that endpoint to invoke and experiment with the APIs.
Python runtime for Knative Functions¶
Once all of the above is running you need to create your Knative Functions project. We are using the CloudEvent template for the new functions runtime for Python.
func create -l python -t cloudevents inference-func
This gives you project that already works and can be locally tested with func run.
My first AI function¶
Our generated function code was updated to use the llama_stack_client python library. Below is the relevant snippet from the pyproject.toml file:
dependencies = [
"httpx",
"cloudevents",
"pytest",
"pytest-asyncio",
"llama-stack-client"
]
Accessing the Llama Stack Server¶
Inside the init function we get access to the URL of the Llama Stack and fetch the available models:
...
self.client = LlamaStackClient(base_url=os.environ.get("LLSD_HOST", "http://localhost:8321"))
models = self.client.models.list()
# Select the first LLM
llm = next(m for m in models if m.model_type == "llm")
self.model_id = llm.identifier
...
The LLSD_HOST is pointing to the address of the Llama Stack instance. If the environment variable is not set it defaults to localhost:8321, which matches our port-forward command. For Kubernetes we configure it like:
func config envs add --name=LLSD_HOST --value=http://llamastackdistribution-sample-service.default.svc.cluster.local:8321
Inference request with Knative Functions¶
The main interaction for the actual inference is done in the handle function, which is executed on every request:
...
# 1) Extract the CloudEvent from the scope
request = scope["event"]
# 2) Create a new CloudEvent as response
response = CloudEvent({
"type": "dev.knative.function.response",
"source": "my/ai/knative/function",
"id": f"response-{request.get('id', 'unknown')}"
})
chat_response = self.client.inference.chat_completion(
model_id=self.model_id,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": request.data["query"]},
],
)
# 3) Set the response's data field to the request event's data field
response.data = {"chat": chat_response.completion_message.content}
# 4) Send the response CloudEvent
# The 'send' method is already decorated with CloudEvent middleware
await send(response)
...
We basically extract a query object from the given JSON payload of the incoming CloudEvent, and put that as our content to the chat_completion function from the Llama Stack inference client. After the inference request is executed we are using the given chat value in our HTTP CloudEvent response and return it. The chat contains the response from the used model.
See the entire code:
# Function
import logging
import os
from cloudevents.http import CloudEvent
from llama_stack_client import LlamaStackClient
def new():
return Function()
class Function:
def __init__(self):
logging.info("Connecting to LLama Stack")
self.client = LlamaStackClient(base_url=os.environ.get("LLSD_HOST", "http://localhost:8321"))
models = self.client.models.list()
# Select the first LLM
llm = next(m for m in models if m.model_type == "llm")
self.model_id = llm.identifier
print("Using Model:", self.model_id)
async def handle(self, scope, receive, send):
logging.info("Request Received")
# 1) Extract the CloudEvent from the scope
request = scope["event"]
# 2) Create a new CloudEvent as response
response = CloudEvent({
"type": "dev.knative.function.response",
"source": "my/ai/knative/function",
"id": f"response-{request.get('id', 'unknown')}"
})
chat_response = self.client.inference.chat_completion(
model_id=self.model_id,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": request.data["query"]},
],
)
# 3) Set the response's data field to the request event's data field
response.data = {"chat": chat_response.completion_message.content}
# 4) Send the response CloudEvent
# The 'send' method is already decorated with CloudEvent middleware
await send(response)
def start(self, cfg):
logging.info("Function starting")
def stop(self):
logging.info("Function stopping")
def alive(self):
return True, "Alive"
def ready(self):
return True, "Ready"
NOTE: the docstrings were remove to keep the program compact.
First contact¶
We can now run our function locally by issuing func run on the command line. Once it is running there will a system log like below:
INFO:root:Functions middleware invoking user function
INFO:root:Connecting to LLama Stack
INFO:httpx:HTTP Request: GET http://localhost:8321/v1/models "HTTP/1.1 200 OK"
Using Model: llama3.2:1b
INFO:root:function starting on ['127.0.0.1:8080']
INFO:root:Function starting
[2025-07-04 14:22:05 +0200] [38829] [INFO] Running on http://127.0.0.1:8080 (CTRL + C to quit)
INFO:hypercorn.error:Running on http://127.0.0.1:8080 (CTRL + C to quit)
Running on host port 8080
Now we can send a CloudEvent to the function, which contains our query for the AI model inference. In a new terminal of the function project we use func invoke for this:
func invoke -f=cloudevent --data='{"query":"Tell me a dad joke!"}'
Context Attributes,
specversion: 1.0
type: dev.knative.function.response
source: https://knative.dev/python-function-response
id: response-b2bf2fd6-600b-49a9-9644-a86e119d0873
time: 2025-07-04T12:35:49.985942Z
Data,
{"chat": "Here's one:\n\nWhy couldn't the bicycle stand up by itself?\n\n(wait for it...)\n\nBecause it was two-tired!\n\nHope that made you groan and laugh! Do you want another one?"}
We see that the function was returning a different CloudEvent, which contains the chat object in its body, which is a joke that we got from the LLama model.
Kubernetes¶
To deploy the function to our kind cluster you need to install Knative Serving. The Llama Stack Stack repo has a script for this as well. Once it is installed simply run:
func deploy --builder=host --build
This builds the function, using the host builder, pushes it to the container registry and eventually deploys it as a Knative Serving Service on Kubernetes:
🙌 Function built: quay.io/<my-func-org>/inference-func:latest
pushing 100% |████████████████████████████████████████| (175/121 MB, 24 MB/s) [7s]
✅ Function deployed in namespace "default" and exposed at URL:
http://inference-func.default.svc.cluster.local
We can now use the exact same func invoke command to also test the Knative Function.
Note: The container registry is configurable via the $FUNC_REGISTRY environment variable on the computer.
Conclusion¶
We have seen that the new Python runtime for Knative Functions is handling AI integrations very nicely. The functions have a well defined lifecycle for various aspects of AI applications. The Llama Stack libraries could be used to access a standardized AI stack: Llama Stack.
To learn more about Knative Functions visit the documentation on our website or join our CNCF Slack channel #knative-functions!
Enjoy!