Serverless workloads using Knative¶
Author: Mark Chmarny, TL for Cloud OSS @Google
By now, Kubernetes should be the default target for your deployments. Yes, there are still use-cases where Kubernetes is not the optimal choice, but these represent an increasingly smaller number of modern workloads.
The main value of Kubernetes is that it greatly abstracts much of the infrastructure management pain. The broad support amongst virtually all major Cloud Service Providers (CSP) also means that your workloads are portable. Combined with the already vibrant ecosystem of Kubernetes-related tools, means that the experience of the operator, the person responsible for managing Kubernetes, is now pretty smooth.
But what about the experience of the developer, the person who builds solutions on top of Kubernetes?
Despite what some might tell you, Kubernetes is not yet today’s application server. For starters, the act of developing, deploying and managing services on Kubernetes is still too complicated. Yes, there are many open source projects for logging, monitoring, integration, etc., but, even if you put these together just right, the experience of developing on Kubernetes is still fragile and way too labour-intensive.
As if that wasn’t enough, the growing popularity of functions as the atomic unit of code development further contributes to the overall complexity. Often creating different development patterns on two disconnected surface areas:one for functions (FaaS) and one for applications (PaaS).
As the result, developers today are being forced to worry about infrastructure-related concerns: such as, image building, registry publishing, deployment services, load balancing, logging, monitoring, and scaling. However, what all they really want to do is write code.
Introducing Knative

At Google Cloud Next in San Francisco this week, Google announced an early preview of the GKE serverless add-on (g.co/serverlessaddon). Google also open-sourced Knative (kay-nay-tiv), the project that powers the serverless add-on (github.com/knative).
Knative implements many of the learnings from Google. The open source project already has contributions from companies like Pivotal, IBM, Red Hat and SAP and collaboration with open-source Function-as-a-Service framework communities like OpenWhisk, riff, and Kyma who either replatform on to Knative or consume one or more components from the Knative project.
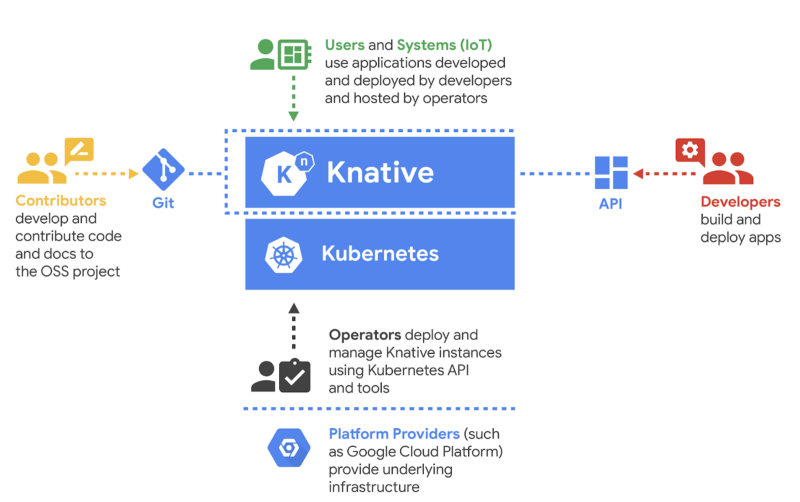
Knative helps developers build, deploy, and manage modern serverless workloads on Kubernetes.
It provides a set of building blocks that enable modern, source-centric and container-based development workloads on Kubernetes:
- Build — Source-to-container build orchestration
- Eventing — Management and delivery of events
- Serving — Request-driven compute that can scale to zero
Knative documentation provides instructions on how to install it on hosted Kubernetes offering like Google Cloud Platform or IBM, and on-prem Kubernetes installations, like the one offered by Pivotal. Finally, Knative repository also includes samples and how-to instructions to get you started developing on Kubernetes.
Knative Overview
Knative is based on the premise of clear separation of concerns. It allows developers and operators to reason about the workload development, deployment, and management by defining primitive objects in a form of Custom Resource Definitions (CRDs) which extend on the object model found in Kubernetes.
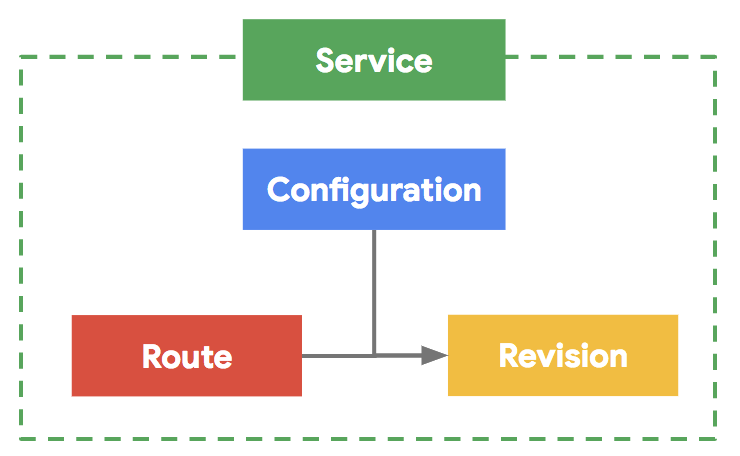
- Configuration — is the desired state for your service, both code and configuration
- Revision — represents an immutable point-in-time snapshot of your code and configuration
- Route — assigns traffic to a revision or revisions of your service
- Service — is the combined lite version of all the above objects to enable simple use cases
In addition to these objects, Knative also defines principle objects for eventing… you know, because serverless. Knative decouples event producers and consumers and implements CNCF CloudEvents (v0.1) to streamline event processing.
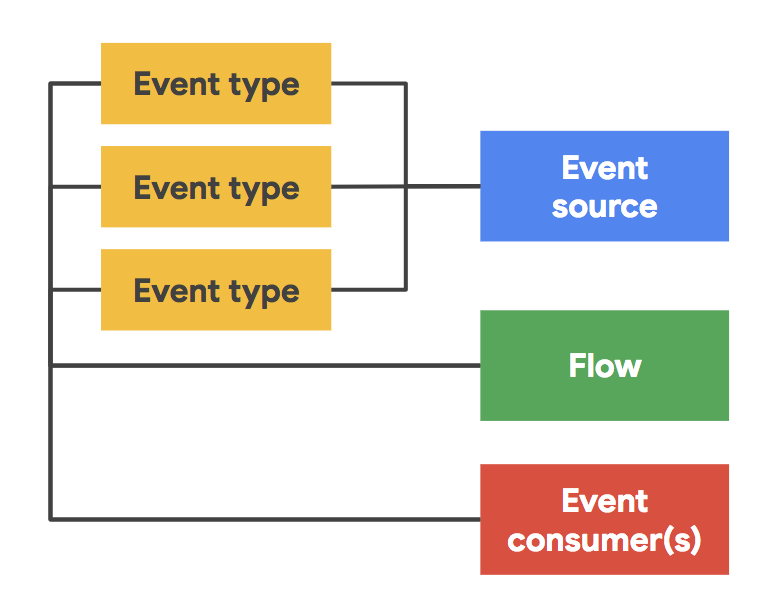
- Event Sources — represents the producer of events (e.g. GitHub)
- Event Types — describes the types of events supported by the different event sources (e.g. Webhook for the above mentioned GitHub source)
- Event Consumers — represents the target of your action (i.e. any route defined by Knative)
- Event Feeds — is the binding or configuration connecting the event types to actions
The functional implementation of the Knative object model means that Knative is both easy to start with, but capable enough to address more advanced use cases as the complexity of your solutions increases.
Summary
I hope this introduction gave you an understanding of the value of Knative. And how the Knative objects streamline development on Kubernetes, regardless if you work on applications or functions.
Over the next few weeks I will be covering each one of the key Knative usage patterns (image push, blue/green deployment model, source to URL, etc). In each post, I will also provide a sample code to illustrate that pattern and allow you to reproduce them on Knative. I’m super excited to share Knative with you, and I hope you come back to find out more.